
티스토리 뷰
내장 함수
내장 함수
- 내장 함수는 DBMS에서 제공하는 기본적인 함수들로 데이터 처리 및 쿼리 작업을 수행하는데 사용됩니다.
- 내장 함수는 크게 2가지로 나뉘어 집니다.
- 단일 행 함수: 문자형 함수, 숫자형 함수, 날짜형 함수, 형 변환 함수, NULL 관련 함수
- 다중 행 함수: 집계 함수, 그룹 함수, 윈도우 함수
단일 행 함수
단일 행 함수에는 문자형, 숫자형, 날짜형, 형 변환, NULL 관련 함수가 있습니다.
1. 문자형 함수
문자형 함수는 문자 또는 문자열을 입력받아 처리하는 함수로, SELECT, WHERE, ORDER BY 절에서 사용할 수 있습니다.
| 함수 | 설명 |
| LOWER(문자열) | 문자열을 소문자로 변환합니다. |
| UPPER(문자열) | 문자열을 대문자로 변환합니다. |
| INITCAP(문자열) | 문자열의 첫 문자를 대문자로 변환합니다. (Pascal Case) |
| ASCII(문자) | 문자를 아스키 코드로 변환합니다. |
| CHR(아스키 코드) | 아스키 코드를 문자로 변환합니다. SQL Server에서는 CHAR()를 사용합니다. |
| CONCAT(문자열1, 문자열2) | 문자열1과 문자열2를 연결합니다. '문자열1' | | '문자열2' 와 같습니다. |
| SUBSTR(문자열, 시작위치[, 길이]) | 문자열의 시작위치에서 길이만큼 반환하며, 길이를 생략하면 마지막 문자열까지 반환합니다. 시작위치를 음수로 입력하면 오른쪽 방향으로 계산하여 출력되며, SQL Server에서는 SUBSTRING()을 사용합니다. |
| LENGTH(문자열) | 문자열의 길이를 출력합니다. 바이트를 반환하려면 LENGTHB()를 사용하며, SQL Server에서는 LEN()을 사용합니다. |
| LTRIM(문자열[, 지정문자]) | 문자열의 왼쪽에서 연속되는 지정문자를 제거하며, 지정문자가 생략되면 공백을 제거합니다. |
| RTRIM(문자열[, 지정문자]) | 문자열의 오른쪽에서 연속되는 지정문자를 제거하며, 지정문자가 생략되면 공백을 제거합니다. |
| TRIM([LEADING | TRAILING | BOTH] [지정문자 FROM] 문자열) |
문자열의 머릿말, 꼬릿말 또는 양쪽에서 지정문자를 제거하며, 지정문자를 생략하면 공백을 제거합니다. |
| LPAD(문자열, 길이[, 채움문자]) | 길이만큼 문자열의 왼쪽에 채움문자를 채우며, 채움문자를 생략하면 공백을 채웁니다. |
| RPAD(문자열, 길이[, 채움문자]) | 길이만큼 문자열의 오른쪽에 채움문자를 채우며, 채움문자를 생략하면 공백을 채웁니다. |
| REPLACE(문자열, 지정문자열, 변환문자열) | 문자열에서 지정문자열을 변환문자열로 변경합니다. |
| TRANSLATE(문자열, 지정문자열, 변환문자열) | REPLACE와 유사하며, 지정문자열의 한글자씩 변환문자열에 매핑하여 문자열을 변경합니다. |
2. 숫자형 함수
숫자형 함수는 수치형 데이터를 입력받아 처리하는 함수입니다.
| 함수 | 설명 |
| ABS(숫자) | 숫자의 절대값을 반환합니다. |
| SIGN(숫자) | 숫자가 양수이면 1, 음수이면 -1, 0이면 0을 반환합니다. |
| MOD(숫자1, 숫자2) | 숫자1을 숫자2로 나눈 나머지를 반환합니다. |
| CEIL(숫자) | 숫자의 올림값을 반환합니다. |
| FLOOR(숫자) | 숫자의 내림값을 반환합니다. |
| ROUND(숫자[, 소수점자리수]) | 숫자를 소수점 자릿수에서 반올림합니다. 소수점자리수를 생략하면 기본값으로 0이 적용됩니다. |
| TRUNC(숫자[, 소수점자리수]) | 숫자의 소수점 자릿수 뒷자리를 버립니다. |
3.날짜 및 시간 함수
날짜형 함수는 DATE 타입의 데이터를 계산합니다.
| 함수 | 설명 |
| SYSDATE | 현재 날짜와 시간을 반환합니다. SQL Server에서는 GETDATE()를 사용합니다. |
| EXTRACT (YEAR | MONTH | DAY FROM 날짜) |
날짜에서 년(YEAR), 월(MONTH), 일(DAY)을 추출합니다. SQL Server에서는 DATEPART()를 사용합니다. |
4. 형 변환 함수
형 변환 함수는 데이터 타입을 변환하기 위해 사용하는 함수입니다.
| 함수 | 설명 |
| TO_NUMBER(문자열) | 문자열을 숫자로 변환합니다. |
| TO_CHAR(숫자 | 날짜[, 포맷]) | 숫자 또는 날짜를 포맷에 맞는 문자열로 변환합니다. |
| TO_DATE(문자열[, 포맷]) | 문자열을 포맷에 맞는 날짜 타입으로 변환합니다. |
5. NULL 관련 함수
| 함수 | 내용 |
| NVL(표현식1, 표현식2) | 표현식1이 NULL이면 표현식2를 반환합니다. SQL Server에서는 ISNULL()을 사용합니다. |
| NVL2(표현식1, 표현식2, 표현식3) | 표현식1이 NULL이 아니면 표현식2를, NULL이면 표현식3을 반환합니다. |
| IFNULL(표현식1, 표현식2) | 표현식1과 표현식2가 같으면 NULL을, 같지않으면 표현식1을 반환합니다. |
| COALESE(표현식1, 표현식2, …) | 표현식 중 NULL이 아닌 첫번째 값을 반환합니다. |
다중 행 함수
다중 행 함수의 유형은 집계 함수, 그룹 함수, 윈도우 함수가 있습니다.
1. 집계 함수
집계 함수는 특정 Column에 대한 행들의 값을 통계적으로 계산한 결과를 반환하는 함수입니다.
SELECT 절, HAVING 절, GROUP BY 절에 사용할 수 있으며, 값은 제외하고 계산됩니다.
| 함수 | 설명 |
| COUNT(*) | 값을 포함한 컬럼 전체 행의 수를 반환합니다. |
| COUNT(컬럼 | 표현식) | 값을 제외한 컬럼이나 표현식에 해당하는 행의 수를 반환합니다. |
| SUM(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값의 합계를 반환합니다. |
| AVG(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값의 평균을 반환합니다. |
| MAX(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값 중 최대값을 반환합니다. |
| MIN(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값 중 최소값을 반환합니다. |
| STDDEV(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값들의 표준편차를 반환합니다. |
| VARIANCE(컬럼 | 표현식) | 컬럼이나 표현식에 해당하는 값들의 분산을 반환합니다. |
2. 그룹 함수
그룹 함수는 데이터를 그룹화하고 각 그룹 내의 데이터를 분석하는 데 사용되는 함수입니다.
SELECT 문에서 사용되며 일반적으로 GRUOP BY 구문과 함께 사용되며 ROLLUP, CUBE, GROUPPING SETS와 같은 함수가 이에 해당합니다.
우선 다음과 같은 그룹함수를 사용할 월별매출 테이블이 있다고 가정하겠습니다.
CREATE TABLE 월별매출 ( 상품ID VARCHAR2(5),
월 VARCHAR2(10),
회사 VARCHAR2(10),
매출액 INTEGER );
INSERT INTO 월별매출 VALUES ('P001', '2019.10', '삼성', 15000);
INSERT INTO 월별매출 VALUES ('P001', '2019.11', '삼성', 25000);
INSERT INTO 월별매출 VALUES ('P002', '2019.10', 'LG', 10000);
INSERT INTO 월별매출 VALUES ('P002', '2019.11', 'LG', 20000);
INSERT INTO 월별매출 VALUES ('P003', '2019.10', '애플', 15000);
INSERT INTO 월별매출 VALUES ('P003', '2019.11', '애플', 10000);
SELECT * FROM 월별매출;
GROUP BY 절
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY 상품ID, 월;
그룹 함수를 사용하기 전 단순한 GROUP BY 절을 실행해 보겠습니다.
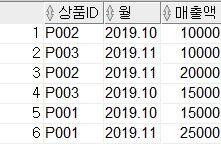
GROUP BY의 결과를 살펴 보면 GROUP으로 묶은 상품 ID, 월 기준으로 그룹화가 되는 것을 볼 수 있습니다.
ROLLUP 함수
ROLLUP 함수는 지정된 컬럼의 소계 및 총계를 구하기 위해 사용하는 그룹 함수입니다.
각 열을 기준으로 데이터를 그룹화하고, 각 그룹에 대해 집계 연산을 수행한 다음, 상위 수준에서도 그룹화 및 집계를 수행합니다.
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(상품ID, 월);
위 SQL문을 실행한 결과 다음과 같은 결과를 얻을 수 있었습니다.

단순히 GROUP BY 절을 실행했을 때와는 다르게 소계와 총계가 같이 나오는 것을 알 수 있습니다.
따라서, ROLLUP 함수를 쓰면 상품 ID별 전체 매출액, 상품 ID와 월별 매출액의 합계, 전체 매출액의 총계 결과를 얻을 수 있습니다. 또한, ROLLUP 함수는 인수의 순서에도 영향을 받습니다.
이번에는 월, 상품 ID로 인자의 순서를 바꿔서 실행 해보겠습니다.
SELECT 월, 상품ID, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(월, 상품ID);
아까와는 반대로 월 별 전체 매출액, 해당 월에 대한 상품 ID별의 매출액, 전체 매출액의 총계의 결과를 얻을 수 있었습니다.
CUBE 함수
CUBE 함수는 다차원 그룹화를 수행하기 위한 기능입니다.
ROLLUP 함수와 마찬가지로 GROUP BY 절에 사용되며, 여러 열을 기준으로 데이터를 그룹화하고 각 그룹 단위의 합계를 계산합니다.
하지만, ROLLUP 함수와 달리 CUBE 함수는 모든 가능한 조합에 대한 그룹 단위의 합계를 계산합니다.
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY CUBE(상품ID, 월);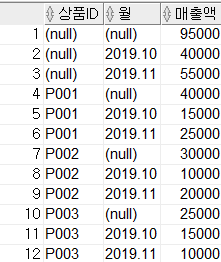
ROLLUP을 사용할 때보다 결과 건수가 더 많아졌습니다. CUBE 함수는 그룹핑 Column이 가질 수 있는 모든 경우의 수에 대하여 소계와 총계를 생성합니다. 따라서, ROLLUP과 다르게 인자의 순서가 달라도 결과는 같습니다.
결과를 살펴보면 상품 ID 별 소계, 월 별 소계, 상품 ID와 월 별의 매출액 소계, 전체 매출액의 총계로 나타납니다.
GROUPING SETS 함수
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY GROUPING SETS(상품ID, 월);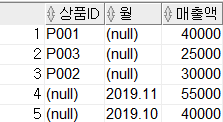
GROUPING SETS의 결과를 살펴보면 상품ID 별 소계, 월 별 소계가 나오는 것을 확인할 수 있습니다.
GROUPING SETS는 ROLLUP과 CUBE와 달리 계층 구조가 나타나지 않으며 인자의 순서가 달라도 결과는 똑같습니다.
또한, GROUPING SETS는 괄호로 묶은 집합 별로도 집계를 구할 수 있습니다.
SELECT 상품ID, 월, 회사, SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY GROUPING SETS((상품ID, 월), 회사);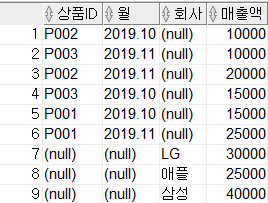
묶여진 Column을 하나의 인자로 취급하여 (상품 ID, 월) 별의 소계와 회사 별 소계가 나오는 것을 확인할 수 있습니다.
+ GROUPING 함수
GROUPING 함수는 직접 그룹별 집계를 구하지는 않지만 앞서 설명한 ROLLUP, CUBE, GROUPING SETS를 지원하는 역할을 합니다.
GROUPING (표현식) = 1이 되며, 그 외에는 GROUPING = 0이 됩니다.
SELECT
CASE GROUPING(상품ID) WHEN 1 THEN '모든 상품ID' ELSE 상품ID END AS 상품ID,
CASE GROUPING(월) WHEN 1 THEN '모든 월' ELSE 월 END AS 월,
SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY ROLLUP(상품ID, 월);
CASE 함수와 ROLLUP 함수를 응용해서 위와 같은 표현도 가능합니다.
WHEN 1은 상품 ID가 NULL일 때를 의미합니다. 이 경우 '모든 상품ID' 라는 문자열을 반환합니다. 그렇지 않은 경우(=NULL이 아닌 경우)에는 해당 상품ID를 반환합니다.
이는 CUBE, GROUPING SETS 함수에서도 마찬가지로 응용해볼 수 있습니다.
SELECT
CASE GROUPING(상품ID) WHEN 1 THEN '모든 상품ID' ELSE 상품ID END AS 상품ID,
CASE GROUPING(월) WHEN 1 THEN '모든 월' ELSE 월 END AS 월,
SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY CUBE(상품ID, 월);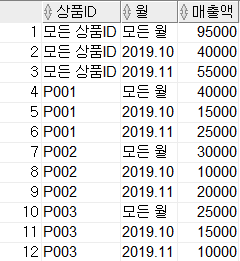
SELECT
CASE GROUPING(상품ID) WHEN 1 THEN '모든 상품ID' ELSE 상품ID END AS 상품ID,
CASE GROUPING(월) WHEN 1 THEN '모든 월' ELSE 월 END AS 월,
CASE GROUPING(회사) WHEN 1 THEN '모든 회사' ELSE 회사 END AS 회사,
SUM(매출액) AS 매출액
FROM 월별매출
GROUP BY GROUPING SETS((상품ID, 월), 회사);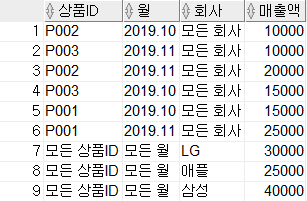
3. 윈도우 함수
윈도우 함수는 OVER 절을 사용하여 데이터 집합을 기반으로 계산되는 함수입니다.
집계 함수와 달리 그룹화하지 않고 개별 행에 대해 계산합니다. 각 행의 계산 결과는 해당 행의 윈도우에 속하는 모든 행의 값을 사용하여 계산 됩니다.
윈도우 함수를 사용하면 데이터 집합에서 개별 행에 대한 값을 계산하는 것이 가능합니다. 일반적으로, 윈도우 함수는 데이터 집합에서 일부 행에 대한 통계를 계산하기 위해 사용됩니다.
윈도우 함수는 행과 행 사이에서 연산을 수행하고 결과 집합에 포함될 행을 결정하는 데 사용됩니다.
데이터베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해 추가된 기능으로 OLAP(On-Line Analytical Processing) 함수라고도 합니다.
윈도우 함수 구문
SELECT 윈도우함수(인수) OEVER (
[PARTITION BY 컬럼1 [, 컬럼2 ...]]
[ORDER BY 컬럼1 [ASC|DESC] [, 컬럼2 [ASC, DESC] ...]]
[WINDOWING절] )
FROM 테이블명;
윈도우 함수를 사용하려면 OVER() 구문을 사용하여 윈도우를 정의해야 합니다. 윈도우는 연산을 수행할 데이터의 범위를 지정하며, 연산 범위는 WINDOWING 절에서 ROWS나 RANGE로 정의됩니다.
ROWS는 행의 수, RANGE는 값의 범위로 윈도우를 정의합니다. ROWS나 RANGE 구문 뒤에는 윈도우의 크기를 나타내는 값이 올 수 있습니다.
WINDOWING 절 구문
[ROWS|RANGE] BETWEEN 시작점 AND 끝점;
시작점은 다음과 같은 키워드를 사용합니다.
| 키워드 | 설명 |
| UNBOUNDED PRECEDING | 최초의 레코드 |
| CURRENT ROW | 현재의 레코드 |
| 값 PRECEDING | 값만큼 이전의 레코드 |
| 값 FOLLOWING | 값만큼 이후의 레코드 |
끝점은 다음과 같은 키워드를 사용합니다.
| 키워드 | 설명 |
| UNBOUNDED FOLLOWING | 마지막 레코드 |
| CURRENT ROW | 현재의 레코드 |
| 값 PRECEDING | 값만큼 이전의 레코드 |
| 값 FOLLOWING | 값만큼 이후의 레코드 |
WINDOWING 절을 명시하지 않은 경우 기본 값으로 RANGE BEWEEN UNBOUNDED PRECENDING AND CURRENTROW가 적용됩니다.
윈도우 함수의 유형에는 순위 함수, 집계 함수, 순서 함수, 비율 함수가 있습니다.
순위 함수
순위 함수는 데이터의 순위를 계산하여 출력합니다.
| 함수 | 설명 |
| RANK | 데이터의 순위를 계산하고, 같은 값이 있을 경우 중복 순위를 건너뛰고 다음 순위를 출력합니다. |
| DENSE_RANK | 데이터의 순위를 계산하고, 같은 값이 있을 경우 중복 순위를 건너뛰지 않고 중복 순위를 포함한 순위를 출력합니다. |
| ROW_NUMBER | 데이터의 순서에 따라 순번을 부여합니다. 같은 값이 있을 경우에도 중복되지 않고 각각의 순번을 출력합니다. |
순위 함수 예제 데이터
다음과 같은 Scores 테이블이 있다고 가정하겠습니다.
| NAME | SCORE |
| Alice | 80 |
| Bob | 80 |
| Carol | 75 |
| Dave | 70 |
1. RANK 함수
SELECT NAME,
SCORE,
RANK() OVER (ORDER BY SCORE DESC) AS RANK
FROM SCORES;RANK() 함수는 동일한 순위를 갖는 데이터가 있을 경우 같은 순위를 부여하고, 그 다음 순위는 건너뛰어 다음으로 높은 순위를 부여합니다.
RANK 함수 결과
| NAME | SCORE | RANK |
| Alice | 80 | 1 |
| Bob | 80 | 1 |
| Carol | 75 | 3 |
| Dave | 70 | 4 |
2. DENSE_RANK 함수
SELECT NAME,
SCORE,
DENSE_RANK() OVER (ORDER BY SCORE DESC) AS RANK
FROM SCORES;DENSE_RANK() 함수는 동일한 순위를 갖는 데이터가 있을 경우 같은 순위를 부여하고, 그 다음 순위를 건너뛰지 않고 동일한 순위를 부여합니다.
DENSE_RANK 함수 결과
| NAME | SCORE | RANK |
| Alice | 80 | 1 |
| Bob | 80 | 1 |
| Carol | 75 | 2 |
| Dave | 70 | 3 |
3. ROW_NUMBER 함수
SELECT NAME,
SCORE,
ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS RANK
FROM SCORES;ROW_NUMBER()는 각 데이터를 유일하게 구별하는 번호를 부여합니다. SCORES 테이블에서 SCORE 칼럼을 기준으로 내림차순으로 정렬한 결과를 기반으로, 각 데이터에 대해 1부터 순차적으로 번호를 부여합니다.
ROW_NUMBER 함수 결과
| 이름 | 점수 | 순위 |
| Alice | 80 | 1 |
| Bob | 80 | 2 |
| Carol | 75 | 3 |
| Dave | 70 | 4 |
ROW_NUMBER() 함수는 특히 페이징 처리에 유용합니다. 페이징 처리란 대량의 데이터를 페이지 단위로 나누어 출력하는 것을 의미합니다.
집계 함수
집계 함수는 파티션 별 윈도우 내에서 데이터를 그룹화하여 통계적으로 계산한 결과를 반환하는 함수입니다.
전체 데이터 셋을 기준으로 계산하는 일반적인 집계 함수와 달리 더욱 세부적인 집계 결과를 얻을 수 있습니다.
집계 함수의 종류
| 함수 | 설명 |
| SUM | 윈도우 내 숫자형 데이터의 합을 계산합니다. |
| AVG | 윈도우 내 숫자형 데이터의 평균을 계산합니다. |
| MIN | 윈도우 내 숫자형 데이터의 최소값을 계산합니다. |
| MAX | 윈도우 내 숫자형 데이터의 최대값을 계산합니다. |
| COUNT | 윈도우 내 데이터의 개수를 계산합니다. |
집계 함수 예시 코드
SELECT NAME,
SUBJECT,
SCORE,
SUM(SCORE) OVER (PARTITION BY SUBJECT) AS SUBJECT_TOTAL_SCORE,
AVG(SCORE) OVER (PARTITION BY SUBJECT) AS SUBJECT_AVG_SCORE,
MIN(SCORE) OVER (PARTITION BY SUBJECT) AS SUBJECT_MIN_SCORE,
MAX(SCORE) OVER (PARTITION BY SUBJECT) AS SUBJECT_MAX_SCORE,
COUNT(SCORE) OVER (PARTITION BY SUBJECT) AS SUBJECT_COUNT_SCORE
FROM SCORES;
순서 함수
순서 함수는 각 행의 이전이나 다음 행의 값을 가져오거나, 윈도우 내에서의 첫 번째나 마지막 값을 가져오는 함수 입니다.
| 함수 | 이름 |
| LAG | 윈도우 내에서 이전 행의 값을 반환합니다. |
| LEAD | 윈도우 내에서 이후 행의 값을 반환합니다. |
| FIRST_VALUE | 윈도우 내에서 첫 번째 값을 반환합니다. |
| LAST_VALUE | 윈도우 내에서 마지막 값을 반환합니다. |
예시 테이블
| ID | DATA | AMOUNT |
| 1 | 2022-01-01 | 100 |
| 2 | 2022-01-02 | 200 |
| 3 | 2022-01-03 | 300 |
| 4 | 2022-01-04 | 400 |
| 5 | 2022-01-05 | 500 |
SELECT ID,
"DATE",
AMOUNT,
LEAD(AMOUNT) OVER (ORDER BY "DATE") AS NEXT_AMOUNT,
LAG(AMOUNT) OVER (ORDER BY "DATE") AS PREV_AMOUNT,
FIRST_VALUE(AMOUNT) OVER (ORDER BY "DATE") AS FIRST_AMOUNT,
LAST_VALUE(AMOUNT) OVER (ORDER BY "DATE") AS LAST_AMOUNT
FROM SALES;
결과
| ID | DATE | AMOUNT | NEXT_AMOUNT | PREV_AMOUNT | FIRST_AMOUNT | LAST_AMOUNT |
| 1 | 2022-01-01 | 100 | 200 | 100 | 100 | |
| 2 | 2022-01-02 | 200 | 300 | 100 | 100 | 200 |
| 3 | 2022-01-03 | 300 | 400 | 200 | 100 | 300 |
| 4 | 2022-01-04 | 400 | 500 | 300 | 100 | 400 |
| 5 | 2022-01-05 | 500 | 400 | 100 | 500 |
파티셔닝 하지 않았기 때문에 전체 행을 하나로 그룹화 합니다. LEAD와 LAG 함수는 직관적으로 알 수 있습니다.
FIRST_VALUE와 LAST_VALUE의 경우 이해가 어려울 수 있는데 앞서 말한 WINDOWING절의 기본 값이 RANGE BETWEEN UNBOUNDED PRECENDING AND CURRENT ROW이기 때문에 위와 같은 결과가 나왔습니다.
처음 행부터 현재 행까지가 하나의 윈도우가 되기 때문에 FIRST_AMOUNT는 항상 첫 번째 행의 AMOUNT인 100이, LAST_AMOUNT는 현재 행의 AMOUNT가 출력됩니다.
비율 함수
비율 함수는 파티션 내 백분율을 계산하거나 비율에 따라 N등분 할 수 있는 함수 입니다.
| 함수 | 설명 |
| RATIO_TO_RERORT | 윈도우 내 SUM 값에 대한 백분율을 계산합니다. |
| PERCENT_RANK | 윈도우 내 순서별 백분율을 계산합니다. |
| CUME_DIST | 윈도우 내 순서별 누적 백분율을 계산합니다. |
| NTILE | 윈도우 내 데이터를 정렬하여 동일한 크기의 버킷으로 분할 한 후 각 버킷에 번호를 할당하는 함수입니다. |
예시 테이블
| ID | DATA | AMOUNT |
| 1 | 2022-01-01 | 100 |
| 2 | 2022-01-02 | 200 |
| 3 | 2022-01-03 | 300 |
| 4 | 2022-01-04 | 400 |
| 5 | 2022-01-05 | 500 |
SELECT ID,
"DATE",
AMOUNT,
RATIO_TO_REPORT(AMOUNT) OVER () AS AMOUNT_SUM_RATIO,
PERCENT_RANK() OVER (ORDER BY "DATE") AS AMOUNT_RATIO,
CUME_DIST() OVER (ORDER BY "DATE") AS AMOUNT_CUM_DIST
FROM SALES;
RATIO_TO_REPORT 함수는 SUM 값을 그룹하기 위한 컬럼을 인수로 설정하고, OVER() 구문에서 ORDER BY 절을 사용하지 않습니다.
반면, PERCENT_RANK와 CUME_DIST 함수는 인수가 없으며, OVER() 구문에서 ORDER BY 절을 통한 정렬이 필요합니다.
결과
| ID | DATE | AMOUNT | AMOUNT_SUM_RATIO | AMOUNT_RATIO | AMOUNT_CUM_DIST |
| 1 | 2022-01-01 | 100 | 0.0666666667 | 0 | 0.2 |
| 2 | 2022-01-02 | 200 | 0.1333333333 | 0.25 | 0.4 |
| 3 | 2022-01-03 | 300 | 0.2 | 0.5 | 0.6 |
| 4 | 2022-01-04 | 400 | 0.2666666667 | 0.75 | 0.8 |
| 5 | 2022-01-05 | 500 | 0.3333333333 | 1 | 1 |
참고
https://huimang2.github.io/sql/built-in-function
SQL - 내장 함수(Built-in Function)
함수(Function) 함수(Function)는 데이터베이스에서 입력값을 처리하여 결과값을 반환하는 프로그램으로, 크게 밴더에서 제공하는 내장 함수(Built-in Function)와 사용자가 작성하는 사용자 정의 함수(Use
huimang2.github.io
https://byul91oh.tistory.com/372
[오라클(Oracle)] 그룹 함수 (ROLLUP, CUBE, GROUPING 등)
오라클에 있는 다양한 그룹함수에 대한 내용이다. CREATE TABLE 월별매출 ( 상품ID VARCHAR2(5), 월 VARCHAR2(10), 회사 VARCHAR2(10), 매출액 INTEGER ); INSERT INTO 월별매출 VALUES ('P001', '2019.10', '삼성', 15000); INSERT IN
byul91oh.tistory.com
'Database > 공통' 카테고리의 다른 글
| [DB]WITHIN GROUP 구문 (0) | 2024.09.27 |
|---|---|
| [DB]집합 관련 연산자(UNION, INTERSECT, MINUS) (0) | 2024.09.19 |
| [DB]Redo와 Undo로 데이터 복구하기 (0) | 2024.08.30 |
| [DB]CLOB과 BLOB (0) | 2024.08.28 |
| [DB]내장 SQL와 커서 (0) | 2024.08.28 |
- Total
- Today
- Yesterday